Headless Chrome でスマホ用画面のテストと、PC画面用テストを行う
イントロ
Headless Chrome で system test を書いていたら、猛烈にハマったので記録を残しておく。
ハマりすぎて Capybara のコードを殆ど読んでしまったので、
読んだ内容を抜粋してまとめてみました。
若干冗長なのはお許し下さい。
環境
rails (5.1.4)capybara (2.17.0)site_prism (2.9)
やりたいこと
- Rails 5.1.4 で system test を使い、spec を書きたい
- 折角なので Headless Chrome を使いたい
- 諸事情で PC 用とスマホ用で画面が違うので、それぞれテストしたい
- PC/スマホ判定は、 UserAgent で行う
イメージとしては、以下のような感じでテストを書いている
RSpec.describe 'Inquiries', type: :system do describe 'GET /inquiries' do context 'PC' do include_context 'view pc browser' it 'has expected elements' do # PC ブラウザでの要素確認 end end context 'smartphone' do include_context 'view smartphone' it 'has expected elements' do # スマホでの要素確認 end end end end
shared_context 'view smartphone' do before do # UserAgent を見て PC/スマホ用の画面切り替えを行っている caps = Selenium::WebDriver::Remote::Capabilities.chrome( 'chromeOptions' => { 'args' => %w(--headless --disable-gpu --user-agent=iPhone) } ) driven_by :selenium, screen_size: [400, 800], options: { desired_capabilities: caps } end end shared_context 'view pc browser' do before do caps = Selenium::WebDriver::Remote::Capabilities.chrome( 'chromeOptions' => { 'args' => %w(--headless --disable-gpu) } ) driven_by :selenium, screen_size: [1400, 2000], options: { desired_capabilities: caps } end end
期待していた結果と、実際の結果
- expected
context 'PC'の中では PC 用 view、context 'smartphone'の中では スマホ用の view をテストする
- actual
include_contextを一度実行した結果を、最後まで保持してしまう- 例えば、最初に
view pc browserを呼ぶと、下のcontext 'smartphone'の中でも、PC 用の view でテストが実行されてしまう
原因を端的にいうと
Capybaraはテスト始まった時に作成した session を、Capybaraクラスにキャッシュしていて、それをテストが終わるまで使い続けるCapybaraは session 作成時にのみ、headless_chrome の初期化を行う- これは、この時点でのみ、
--user-agentとか、--window-size等の option を渡せることを意味する
driven_byを RSpec の before で呼び出しても、それは ruby で評価されないので、反映されない- 何故なら評価されるのは、初回だけだから
コードを読む
長いので、結論だけ見たければ、一番の対処法へジャンプして下さい。
まず、headless_chrome に option を渡している部分が以下。
@processed_options[:args] でその option が渡ってくる。
class Capybara::Selenium::Driver < Capybara::Driver::Base DEFAULT_OPTIONS = { :browser => :firefox, clear_local_storage: false, clear_session_storage: false } SPECIAL_OPTIONS = [:browser, :clear_local_storage, :clear_session_storage] attr_reader :app, :options def browser unless @browser if firefox? options[:desired_capabilities] ||= {} options[:desired_capabilities].merge!({ unexpectedAlertBehaviour: "ignore" }) end # この @processed_option に headless_chrome に渡す option が入っている @processed_options = options.reject { |key,_val| SPECIAL_OPTIONS.include?(key) } @browser = Selenium::WebDriver.for(options[:browser], @processed_options) @w3c = ((defined?(Selenium::WebDriver::Remote::W3CCapabilities) && @browser.capabilities.is_a?(Selenium::WebDriver::Remote::W3CCapabilities)) || (defined?(Selenium::WebDriver::Remote::W3C::Capabilities) && @browser.capabilities.is_a?(Selenium::WebDriver::Remote::W3C::Capabilities))) main = Process.pid at_exit do # Store the exit status of the test run since it goes away after calling the at_exit proc... @exit_status = $!.status if $!.is_a?(SystemExit) quit if Process.pid == main exit @exit_status if @exit_status # Force exit with stored status end end @browser end def initialize(app, options={}) load_selenium @session = nil @app = app @browser = nil @exit_status = nil @frame_handles = {} @options = DEFAULT_OPTIONS.merge(options) end end
@processed_options の中身は以下のようになっている
[7] pry(#<Capybara::Selenium::Driver>)> @processed_options
=> {:desired_capabilities=>
#<Selenium::WebDriver::Remote::Capabilities:0x007f9db391b998
@capabilities=
{:browser_name=>"chrome",
:version=>"",
:platform=>:any,
:javascript_enabled=>true,
:css_selectors_enabled=>true,
:takes_screenshot=>false,
:native_events=>false,
:rotatable=>false,
:firefox_profile=>nil,
:proxy=>nil,
"chromeOptions"=>{"args"=>["--headless", "--disable-gpu"]}}>}
options[:desired_capabilities] は Selenium::WebDriver::Remote::Capabilities インスタンスで、 options[:desired_capabilities]['chromeOptions']['args'] に headless_chrome に渡す option が文字列で定義されている。
これは ヘッドレス Chrome ことはじめ | Web | Google Developers に書かれている option で、ここをいじれば色々なことができる。
テスト実行されると、回りに回って Capybara::Selenium::Driver#browser が呼ばれるのだが、一旦話は戻って一番最初の shared_context の中に戻る。
この shared_context 内で before を定義しているので、example の実行前に driven_by が呼ばれる。
driven_by の定義は以下。 SystemTesting::Driver を new している。
# System Test configuration options # # The default settings are Selenium, using Chrome, with a screen size # of 1400x1400. # # Examples: # # driven_by :poltergeist # # driven_by :selenium, using: :firefox # # driven_by :selenium, screen_size: [800, 800] def self.driven_by(driver, using: :chrome, screen_size: [1400, 1400], options: {}) self.driver = SystemTesting::Driver.new(driver, using: using, screen_size: screen_size, options: options) end
SystemTesting::Driver は以下のようになっている
new された後、途中経過は色々あるが、ActionDispatch::SystemTesting::Driver#use が呼ばれる。
module ActionDispatch module SystemTesting class Driver # :nodoc: def initialize(name, **options) @name = name @browser = options[:using] @screen_size = options[:screen_size] @options = options[:options] end def use register if registerable? setup end private def registerable? [:selenium, :poltergeist, :webkit].include?(@name) end def register Capybara.register_driver @name do |app| case @name when :selenium then register_selenium(app) when :poltergeist then register_poltergeist(app) when :webkit then register_webkit(app) end end end def register_selenium(app) Capybara::Selenium::Driver.new(app, { browser: @browser }.merge(@options)).tap do |driver| driver.browser.manage.window.size = Selenium::WebDriver::Dimension.new(*@screen_size) end end def register_poltergeist(app) Capybara::Poltergeist::Driver.new(app, @options.merge(window_size: @screen_size)) end def register_webkit(app) Capybara::Webkit::Driver.new(app, Capybara::Webkit::Configuration.to_hash.merge(@options)).tap do |driver| driver.resize_window(*@screen_size) end end def setup Capybara.current_driver = @name end end end end
ActionDispatch::SystemTesting::Driver#use は ActionDispatch::SystemTesting::Driver#register を呼ぶが、ここで奇妙なことがわかる。
def register puts "register!!!" #=> before で毎回呼ばれる Capybara.register_driver @name do |app| puts @name #=> before で毎回呼ばれない??? case @name when :selenium then register_selenium(app) when :poltergeist then register_poltergeist(app) when :webkit then register_webkit(app) end end end
register が毎回 before で呼ばれているにも関わらず、この block が毎回呼ばれない。
これさえ呼ばれれば、--user-agent 付きで Capybara::Selenium::Driver が初期化されるので、example 毎にブラウザを切り替えることができると思うのだが。
で、何故呼ばれないかというと、register_driver された評価済みのブロックがキャッシュされているから。
順に追っていくと、まずは Capybara.register_driver の実装。
module Capybara class << self extend Forwardable ## # # Register a new driver for Capybara. # # Capybara.register_driver :rack_test do |app| # Capybara::RackTest::Driver.new(app) # end # # @param [Symbol] name The name of the new driver # @yield [app] This block takes a rack app and returns a Capybara driver # @yieldparam [<Rack>] app The rack application that this driver runs against. May be nil. # @yieldreturn [Capybara::Driver::Base] A Capybara driver instance # def register_driver(name, &block) drivers[name] = block end def drivers @drivers ||= {} end end end
ただ単に drivers という Hash に詰め込んでいるだけ。 で、この block がいつ評価されるかというと、以下の場所。
module Capybara class Session include Capybara::SessionMatchers attr_reader :mode, :app, :server attr_accessor :synchronized def initialize(mode, app=nil) raise TypeError, "The second parameter to Session::new should be a rack app if passed." if app && !app.respond_to?(:call) @@instance_created = true @mode = mode @app = app if block_given? raise "A configuration block is only accepted when Capybara.threadsafe == true" unless Capybara.threadsafe yield config if block_given? end if config.run_server and @app and driver.needs_server? @server = Capybara::Server.new(@app, config.server_port, config.server_host, config.server_errors).boot else @server = nil end @touched = false end def driver @driver ||= begin unless Capybara.drivers.has_key?(mode) other_drivers = Capybara.drivers.keys.map { |key| key.inspect } raise Capybara::DriverNotFoundError, "no driver called #{mode.inspect} was found, available drivers: #{other_drivers.join(', ')}" end driver = Capybara.drivers[mode].call(app) #=> ここで評価している driver.session = self if driver.respond_to?(:session=) driver end end end end
ここで Capybara::Session#driver で register_driver で格納されたブロックが評価されて、Capybara::Session インスタンスにキャッシュされる。
で、この session インスタンスは Capybara.current_session で初期化され、RSpec のテスト実行中、ずっと使い回される。
その理由は以下。
module Capybara class << self extend Forwardable ## # # The current Capybara::Session based on what is set as Capybara.app and Capybara.current_driver # # @return [Capybara::Session] The currently used session # def current_session session_pool["#{current_driver}:#{session_name}:#{app.object_id}"] ||= Capybara::Session.new(current_driver, app) end def session_pool @session_pool ||= {} end end end
以下はテスト中で Capybara.current_session が使われている部分
module Capybara
module DSL
def page
Capybara.current_session
end
# Session::DSL_METHODS には visit とか within とか、毎度お馴染みのメソッドが配列になっている
# これらのメソッド全て、`Capybara.current_session` がレシーバーで呼び出されている
Session::DSL_METHODS.each do |method|
define_method method do |*args, &block|
page.send method, *args, &block
end
end
end
end
今は natritmeyer/site_prism を使っているけど、そこでもやっぱり Capybara.current_session が使われている
module SitePrism class Page def page @page || Capybara.current_session end end end
ということで、before で何度 driven_by を宣言しようが、一度作成した driver はキャッシュされ、使い続けるような実装になっている
試したこと
キャッシュされている場所はわかったので after で強引にインスタンス変数を消し去ってみる
shared_context 'view pc browser' do before do caps = Selenium::WebDriver::Remote::Capabilities.chrome( 'chromeOptions' => { 'args' => %w(--headless --disable-gpu) } ) driven_by :selenium, screen_size: [1400, 2000], options: { desired_capabilities: caps } end after do # ↓ この辺を試した # Capybara.instance_variable_set(:@session_pool, nil) # Capybara.current_session.reset! # Capybara.current_session.driver.quit # Capybara.current_session.instance_variable_set(:@driver, nil) end end
しかし、ブラウザが真っ白になったりして、通るはずのテストで落ちるようになってしまって断念。 流石にアクセサやメソッドが用意されてない中で、こんな無茶苦茶な事やったら駄目みたいだ。
結局どうなったか
この強引なアプローチが駄目だったので、渋々複数の session を管理して、example 実行時に切り替えるようにした。
# around で session_name の一時的変更を行うようにした shared_context 'view smartphone' do around do |example| caps = Selenium::WebDriver::Remote::Capabilities.chrome( 'chromeOptions' => { 'args' => %w(--headless --disable-gpu --user-agent=iPhone) } ) driven_by :selenium, screen_size: [400, 800], options: { desired_capabilities: caps } old_session_name = Capybara.session_name Capybara.session_name = :smartphone_browser example.run Capybara.session_name = old_session_name end end shared_context 'view pc browser' do around do |example| caps = Selenium::WebDriver::Remote::Capabilities.chrome( 'chromeOptions' => { 'args' => %w(--headless --disable-gpu) } ) driven_by :selenium, screen_size: [1400, 2000], options: { desired_capabilities: caps } old_session_name = Capybara.session_name Capybara.session_name = :pc_browser example.run Capybara.session_name = old_session_name end end
# ここは一切変えてない RSpec.describe 'Inquiries', type: :system do describe 'GET /inquiries' do context 'PC' do include_context 'view pc browser' it 'has expected elements' do # PC ブラウザで要素確認できている end end context 'smartphone' do include_context 'view smartphone' it 'has expected elements' do # スマホで要素確認できている end end end end
Capybara.current_session の実装が、
module Capybara class << self extend Forwardable ## # # The current Capybara::Session based on what is set as Capybara.app and Capybara.current_driver # # @return [Capybara::Session] The currently used session # def current_session session_pool["#{current_driver}:#{session_name}:#{app.object_id}"] ||= Capybara::Session.new(current_driver, app) end def session_pool @session_pool ||= {} end end end
となっていたので、session_name さえ変えてあげれば、新たに Capybara::Session が作成される、という事になる。
こんなやり方で良いのだろうか...?
まとめ
Capybara::Sessionは、テスト実行中ずっとキャッシュされる- 別の Session、或いは driver を使いたければ(別の driver とは、option の変更も含む)、別の名前で
Capybara::Sessionを作って、テスト毎に切り替える
port やプロセスの状況を確認するコマンドレシピ集
イントロ
毎回忘れてググるやつをまとめました。
巷では Advent Calendar などが流行っている時期ですが、そんなことはいざ知れず、空気を読まずに普通に投稿します。
ただの netstat, lsof コマンドの使い方をまとめたもの。
- イントロ
- 指定した port 番号から、それを使用している process を特定する
- 指定の process から、どの port を使用しているかを確認する
- 指定の process が、どのファイルを開いているかを確認する
- 開いているファイルから、プロセスを確認する
- ローカルで待ち受けている port 一覧
- 指定の port で process が待ち受けてるかどうか
- 参考
指定した port 番号から、それを使用している process を特定する
port -> process の確認
lsof は環境によってはデフォルトで入ってなかったりするので、その場合は netstat を使う。
(こういうケースがあるから覚えにくい)
lsof -i:{port}
$ lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 41533 argerich 23u IPv6 0xabbad0913f4fe95 0t0 TCP localhost:hbci (LISTEN) ruby 41533 argerich 24u IPv4 0xabbad09116bd095 0t0 TCP localhost:hbci (LISTEN)
netstat -anp | grep LISTEN (linux only)
(gentoo の man netstat で確認)
-aは--allの略で、全ての socket を表示-nは--numericの略で、host や port を数字で表示-pは--programで、PID や実行プログラム名を表示する- (
-tは--tcpの略で、tcp で絞り込む) - (
-uは--udpの略で、udp で絞り込む)
2614a2595864 app # netstat -anpt | grep LISTEN tcp 0 0 127.0.0.11:43731 0.0.0.0:* LISTEN -
指定の process から、どの port を使用しているかを確認する
process -> port の確認
lsof -n -P -p {pid} | grep LISTEN
-nは network や host の名前解決を行わない-Pは port 名の変換を行わず、数字で表示する-pは pid で絞り込む
% lsof -P -n -p 206 | grep LISTEN ruby 206 argerich 22u IPv6 0xabbad0913f49e75 0t0 TCP [::1]:3000 (LISTEN) ruby 206 argerich 23u IPv4 0xabbad09148b2cb5 0t0 TCP 127.0.0.1:3000
指定の process が、どのファイルを開いているかを確認する
process -> fd の確認
lsof -p {port}
$ lsof -p 41533 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 41533 argerich cwd DIR 1,4 952 15380291 /Users/argerich/dev/rails-showcase ruby 41533 argerich txt REG 1,4 3245556 24795779 /Users/argerich/.rbenv/versions/2.4.1/bin/ruby ruby 41533 argerich txt REG 1,4 279856 27355077 /System/Library/CoreServices/Encodings/libJapaneseConverter.dylib ruby 41533 argerich txt REG 1,4 13280 24796569 ... ruby 41533 argerich 4 PIPE 0xabbad090c986855 16384 ->0xabbad0907820f15 ruby 41533 argerich 5 PIPE 0xabbad090c986615 16384 ->0xabbad090c985f55 ruby 41533 argerich 6 PIPE 0xabbad090c985f55 16384 ->0xabbad090c986615 ruby 41533 argerich 7w REG 1,4 80408171 15423000 /Users/argerich/dev/rails-showcase/log/development.log ruby 41533 argerich 8 PIPE 0xabbad0907820e55 16384 ->0xabbad090c985e95 ruby 41533 argerich 9u IPv4 0xabbad0906b17285 0t0 TCP 192.168.0.3:60774->54.239.96.26:https (CLOSED) ruby 41533 argerich 10u unix 0xabbad09122853dd 0t0 ->0xabbad090712d18d ruby 41533 argerich 11 PIPE 0xabbad09078206d5 16384 ->0xabbad090c9863d5 ruby 41533 argerich 12u systm 0t0
開いているファイルから、プロセスを確認する
fd -> process の確認
lsof
lsof log/development.log COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 206 argerich 7w REG 1,4 2037258433 26785609 log/development.log
fuser -u
-uは--userの略で、user 名を付与する-vは--verboseの略で、詳細を表示する(linux 限定)
% fuser -u log/development.log log/development.log: 71941(argerich)
4b43c8ebf178 app # fuser -vu /bin/bash
USER PID ACCESS COMMAND
/bin/bash: root 1 ....m (root)bash
ローカルで待ち受けている port 一覧
nmap -v
-vは verbose level を上げる。詳細を表示する、と思って良いのかも-vvもある
- host 部分の指定は
localhost以外にも当然可能- 悪用厳禁
% nmap -v localhost Starting Nmap 7.12 ( https://nmap.org ) at 2017-12-13 21:44 JST Initiating Ping Scan at 21:44 Scanning localhost (127.0.0.1) [2 ports] Completed Ping Scan at 21:44, 0.00s elapsed (1 total hosts) Initiating Connect Scan at 21:44 Scanning localhost (127.0.0.1) [1000 ports] Discovered open port 8080/tcp on 127.0.0.1 Discovered open port 143/tcp on 127.0.0.1 Discovered open port 80/tcp on 127.0.0.1 Discovered open port 110/tcp on 127.0.0.1 Discovered open port 3000/tcp on 127.0.0.1 Discovered open port 3001/tcp on 127.0.0.1 Discovered open port 3128/tcp on 127.0.0.1 Discovered open port 5432/tcp on 127.0.0.1 LOG: could not receive data from client: Connection reset by peer LOG: incomplete startup packet Completed Connect Scan at 21:44, 5.59s elapsed (1000 total ports) Nmap scan report for localhost (127.0.0.1) Host is up (0.00038s latency). Other addresses for localhost (not scanned): ::1 Not shown: 963 closed ports, 29 filtered ports PORT STATE SERVICE 80/tcp open http 110/tcp open pop3 143/tcp open imap 3000/tcp open ppp 3001/tcp open nessus 3128/tcp open squid-http 5432/tcp open postgresql 8080/tcp open http-proxy Read data files from: /Users/argerich/.homebrew/bin/../share/nmap Nmap done: 1 IP address (1 host up) scanned in 5.63 seconds
netstat -ant | grep LISTEN | grep "127.0.0.1"
一覧を出して grep してるだけ。
(nmap と結果が違っている理由がよくわからないけど)
% netstat -ant | grep LISTEN | grep "127.0.0.1" tcp4 0 0 127.0.0.1.3000 *.* LISTEN tcp4 0 0 127.0.0.1.5432 *.* LISTEN tcp4 0 0 127.0.0.1.17603 *.* LISTEN tcp4 0 0 127.0.0.1.17600 *.* LISTEN tcp4 0 0 127.0.0.1.6263 *.* LISTEN tcp4 0 0 127.0.0.1.6258 *.* LISTEN tcp4 0 0 127.0.0.1.6379 *.* LISTEN
指定の port で process が待ち受けてるかどうか
nc -vz {host} {port}
localhost の部分は、別の host にも置き換えられるので、外部から叩いて確認する事もできる
% nc -vz localhost 3306 found 0 associations found 1 connections: 1: flags=82<CONNECTED,PREFERRED> outif lo0 src ::1 port 61086 dst ::1 port 3306 rank info not available TCP aux info available Connection to localhost port 3306 [tcp/mysql] succeeded!
% nc -vz localhost 1119 nc: connectx to localhost port 1119 (tcp) failed: Connection refused nc: connectx to localhost port 1119 (tcp) failed: Connection refused
参考
unicorn + capistrano 構成で、古いリリースの実行パスを参照し続けてしまう問題
イントロ
今更だけどハマったので書いておく。
I, [2017-11-15T17:45:38.423986 #7537] INFO -- : executing ["/var/www/app/releases/20171115083608/vendor/bundle/ruby/2.4.0/bin/unicorn", "-c", "/var/www/ser
val/current/config/unicorn.rb", "-E", "production", "-D", {15=>#<Kgio::UNIXServer:fd 15>}] (in /var/www/app/releases/20171115084509)
I, [2017-11-15T17:45:38.424276 #7537] INFO -- : [before_exec] path: /var/www/app/current/config
/var/www/app/shared/vendor/bundle/ruby/2.4.0/gems/unicorn-5.3.1/lib/unicorn/http_server.rb:457:in `exec': No such file or directory - /var/www/app/releas
es/20171115083608/vendor/bundle/ruby/2.4.0/bin/unicorn (Errno::ENOENT)
from /var/www/app/shared/vendor/bundle/ruby/2.4.0/gems/unicorn-5.3.1/lib/unicorn/http_server.rb:457:in `block in reexec'
from /var/www/app/shared/vendor/bundle/ruby/2.4.0/gems/unicorn-5.3.1/lib/unicorn/http_server.rb:441:in `fork'
from /var/www/app/shared/vendor/bundle/ruby/2.4.0/gems/unicorn-5.3.1/lib/unicorn/http_server.rb:441:in `reexec'
from /var/www/app/shared/vendor/bundle/ruby/2.4.0/gems/unicorn-5.3.1/lib/unicorn/http_server.rb:306:in `join'
from /var/www/app/current/vendor/bundle/ruby/2.4.0/gems/unicorn-5.3.1/bin/unicorn:126:in `<top (required)>'
from /var/www/app/releases/20171115083608/vendor/bundle/ruby/2.4.0/bin/unicorn:23:in `load'
from /var/www/app/releases/20171115083608/vendor/bundle/ruby/2.4.0/bin/unicorn:23:in `<main>'
E, [2017-11-15T17:45:38.500772 #5794] ERROR -- : reaped #<Process::Status: pid 7537 exit 1> exec()-ed
unicorn + capistrano を使っている環境下で、unicorn を USR2 シグナルを送って再起動すると、 新しく立ち上がった unicorn のプロセスは、自身の実行パスが古いままになっている。
これは unicorn の master プロセスが USR2 シグナルを受け取ると、古い unicorn プロセスが、新しい master プロセスを fork するため。(Signal handling)
ところがこのまま capistrano でデプロイしていくと、維持する世代数(keep_releases)を越えてしまい、起動時のディレクトリは破棄されてしまう。
けど、unicorn 自体は初回起動時のパスで再起動しようとするから、そんなファイルねーよと言われてしまう。
環境
rails + unicorn + capistrano というオーソドックスな構成。
capistrano3-unicorn で unicorn の restart を行っている。
ruby (2.4.1)unicorn (5.3.1)capistrano (3.10.0)capistrano-bundler (1.3.0)capistrano3-unicorn (0.2.1)
対応
bundle_binstubsで shared ディレクトリ以下に、unicorn の実行ファイルを配置する- unicorn の実行パスを固定するため
Unicorn::HttpServer::START_CTX[0]で、上記の固定した実行パスを指定する
# config/deploy.rb set :bundle_binstubs, -> { shared_path.join('bin') }
# config/unicorn.rb app_path = '/var/www/app' Unicorn::HttpServer::START_CTX[0] = File.join(app_path, 'shared/bin/unicorn')
おまけ
Unicorn::HttpServer::START_CTX ってなんだよ、というと unicorn の中で、プロセスを fork する時のコマンド実行に使われている定数っぽい。
https://github.com/defunkt/unicorn/blob/v5.3.1/lib/unicorn/http_server.rb#L441-L458
# reexecutes the START_CTX with a new binary def reexec ... @reexec_pid = fork do listener_fds = listener_sockets ENV['UNICORN_FD'] = listener_fds.keys.join(',') Dir.chdir(START_CTX[:cwd]) cmd = [ START_CTX[0] ].concat(START_CTX[:argv]) # avoid leaking FDs we don't know about, but let before_exec # unset FD_CLOEXEC, if anything else in the app eventually # relies on FD inheritence. close_sockets_on_exec(listener_fds) # exec(command, hash) works in at least 1.9.1+, but will only be # required in 1.9.4/2.0.0 at earliest. cmd << listener_fds logger.info "executing #{cmd.inspect} (in #{Dir.pwd})" before_exec.call(self) exec(*cmd) end proc_name 'master (old)' end
https://github.com/defunkt/unicorn/blob/v5.3.1/lib/unicorn/http_server.rb#L32-L49
# :startdoc: # We populate this at startup so we can figure out how to reexecute # and upgrade the currently running instance of Unicorn # This Hash is considered a stable interface and changing its contents # will allow you to switch between different installations of Unicorn # or even different installations of the same applications without # downtime. Keys of this constant Hash are described as follows: # # * 0 - the path to the unicorn executable # * :argv - a deep copy of the ARGV array the executable originally saw # * :cwd - the working directory of the application, this is where # you originally started Unicorn. # # To change your unicorn executable to a different path without downtime, # you can set the following in your Unicorn config file, HUP and then # continue with the traditional USR2 + QUIT upgrade steps: # # Unicorn::HttpServer::START_CTX[0] = "/home/bofh/2.3.0/bin/unicorn"
今回は実行パスが毎回変わるパティーンに相当するのかな。
この変更をダウンタイム無しで行うためには、HUP シグナルを送って、reload させてから、USR2 + QUIT シグナルを送れよ、と書かれている。
(USR2 だけで古いプロセスが死ぬように設定している場合は、USR2 だけで良さそうに思える)
結果
# /var/www/app/shared/log/unicorn.stderr.log
I, [2017-11-16T18:17:40.000683 #10785] INFO -- : unlinking existing socket=/var/www/app/current/tmp/sockets/unicorn.sock
I, [2017-11-16T18:17:40.001511 #10785] INFO -- : listening on addr=/var/www/app/current/tmp/sockets/unicorn.sock fd=15
I, [2017-11-16T18:17:40.005369 #10835] INFO -- : worker=0 ready
I, [2017-11-16T18:17:40.006112 #10785] INFO -- : master process ready
I, [2017-11-16T18:17:40.010895 #10838] INFO -- : worker=1 ready
I, [2017-11-16T18:17:40.011886 #10840] INFO -- : worker=2 ready
I, [2017-11-16T18:26:31.321077 #12323] INFO -- : executing ["/var/www/app/shared/bin/unicorn", "-c", "/var/www/app/current/config/unicorn.rb", "-E", "st
aging", "-D", {15=>#<Kgio::UNIXServer:/var/www/app/current/tmp/sockets/unicorn.sock>}] (in /var/www/app/releases/20171116092542)
I, [2017-11-16T18:26:31.646072 #12323] INFO -- : inherited addr=/var/www/app/current/tmp/sockets/unicorn.sock fd=15
I, [2017-11-16T18:26:31.646396 #12323] INFO -- : Refreshing Gem list
これで何度 deploy しても成功するようになりました。
しかしこんなやり方でいいのだろうか?
一先ずこれで capistrano を使っていても、USR2 シグナルで restart できるようになった。
memcached と戦う
イントロ
ゆとり世代なので、今まで redis しか触ったことない人が memcached を使うと、辛すぎて涙が出ます。
素手では戦えなかったので、memcached と戦うため、最低限の武器を揃えました。
公式
- memcached - a distributed memory object caching system
- memcached/memcached: memcached development tree
- wiki にかなり詳しい情報が乗っている
用語
Slabs, Pages, Chunks and Memcached
Slab(= Slab class)
- 起動時にメモリを確保し、特定のサイズで分割されたメモリ領域のことを指す
- 元々は memory の fragmentation を防ぐために設計されたもの
Slabの実体は「 同じサイズのメモリ領域を持つchunkの集合」SlabはSlab Class Nという形式で番号を振って管理される
$ ./memcached -vv slab class 1: chunk size 80 perslab 13107 slab class 2: chunk size 104 perslab 10082 slab class 3: chunk size 136 perslab 7710 slab class 4: chunk size 176 perslab 5957
例)
slab class 1 には chunk size 80 byte が 13107 個存在している。
ところでこの合計は、 80 [byte] * 13107 = 1048560[byte] ≒ 1M であり、デフォルトの page の領域と等しくなる
Chunk
- レコードをキャッシュするためのメモリ領域
- 同サイズの
chunkの集まりがSlab
Item
chunkに保存される value のこと。- ユーザーが memcached に保存する値そのものを指す単語
- 故に
chunkは固定サイズに対し、item は変動値
- 故に
- memcached では、殆どの場合で
chunk=itemで話が通じる気がする
Page
- Slab は複数の Page を持つ
- デフォルトでは
1MBで分割された memcached のメモリ領域 - Slab > Page > Chunk みたいなイメージ
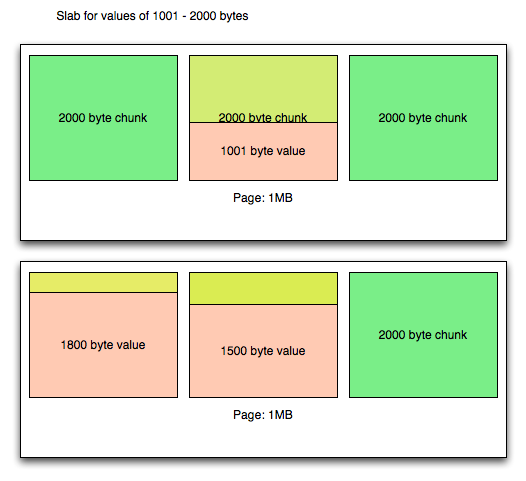
Slabs, Pages, Chunks and Memcached
memcached を触るツールたち
telnet
telnet なんて、学校の授業以来、初めて使ったという。。。
stats item
item 一覧を見る
vagrant@mgi166:~$ telnet localhost 11211 Trying ::1... Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. stats items STAT items:1:number 1 STAT items:1:age 57 STAT items:1:evicted 0 STAT items:1:evicted_nonzero 0 STAT items:1:evicted_time 0 STAT items:1:outofmemory 0 STAT items:1:tailrepairs 0 STAT items:1:reclaimed 0 STAT items:1:expired_unfetched 0 STAT items:1:evicted_unfetched 0 STAT items:1:crawler_reclaimed 0 STAT items:1:crawler_items_checked 0 STAT items:1:lrutail_reflocked 0 END
stats cachedump
対象の slab の item を表示する
# slab 10 の item を 100 個 dump する stats cachedump 10 100 ITEM users_presences [628 b; 1497009430 s] ITEM favorites [540 b; 1497009429 s] ITEM feature_article_categories [509 b; 1497009429 s] ITEM feature_article_tags [568 b; 1497009429 s] ITEM messages_uploaded_files [550 b; 1497009429 s] ITEM services_scores [523 b; 1497009428 s] ITEM favorites_counts [522 b; 1497009428 s] ITEM hyperlinks [578 b; 1497009428 s] ITEM provider_votes [526 b; 1497009429 s] ITEM follows_counts [618 b; 1497009429 s] ITEM follows [541 b; 1497009429 s] ITEM accounts [553 b; 1497009447 s] ITEM services_reservation_users [619 b; 1497009429 s] END
memcached-tool
dump/restore の用途では memcached-tool がよく使われるようだ。
ただの perl script なので、持ってなかったら github から直接取得する。
expired 0 の item が dump できないバグがあるらしいので、気をつける。
$ wget https://raw.githubusercontent.com/memcached/memcached/master/scripts/memcached-tool
$ chmod a+x memcached-tool
$ ./memcached-tool localhost 11211
#localhost:11211 Field Value
accepting_conns 1
auth_cmds 0
auth_errors 0
bytes 0
bytes_read 7
...
uptime 122070
version 1.4.25 Ubuntu
memcacled-cli を使う
memcached-cli の v0.9.4 までの追加機能の紹介 - weblog of key_amb
memcached-cli を使用するのも良いと思う。
大抵の環境では perl 5.8 以上は入っているし、後は carton を入れてローカルに install すれば良い。
telnet よりコマンドが使いやすい。こういうのが欲しかった。
$ apt-get update $ cd /root/home $ mkdir memcached-cli $ apt-get install carton $ apt-get install make $ echo 'requires "App::Memcached::CLI"' > cpanfile $ carton install $ carton exec -- memcached-cli
dump も memcached-tool で取れない expired 0 問題にも対応できている。
# dump $ carton exec -- memcached-cli localhost:11211 dump_all > dump.txt # restore $ carton exec -- memcached-cli localhost:11211 restore_all dump.txt
libmemcached-tools
libmemcached-tools とは memcached の関連ツール群。
(これは apt-get のパッケージ名で、yum でも同じパッケージ名かどうかはわからない)
$ sudo apt-get install libmemcached-tools $ memc # tab で補完させる memcached memccat memcdump memcexist memcparse memcrm memcstat memccapable memccp memcerror memcflush memcping memcslap memctouch
それぞれの使い方は --help でなんとなくわかる。
大体 --servers option が付いていて、これで対象サーバーを指定する。, で複数指定可能。
$ memcdump --help
memdump v1.0
Dump all values from one or many servers.
Current options. A '=' means the option takes a value.
--version
Display the version of the application and then exit.
--help
Display this message and then exit.
--quiet
stderr and stdin will be closed at application startup.
--verbose
Give more details on the progression of the application.
--debug
Provide output only useful for debugging.
--servers=
List which servers you wish to connect to.
--hash=
Select hash type.
--binary
Switch to binary protocol.
--username=
Username to use for SASL authentication
--password=
Password to use for SASL authentication
まとめ
一先ずこれで最低限の操作はできるようになりました。
数ヶ月前、同じ KVM だし key 一覧くらいコマンド一発で見れるやろ、と思っていた自分を殴り倒したいです。
Slab Allocator 周りはゆるく理解したものの、kernel でも使われているとのことなので、もう少し深掘りして理解していきたいところ。
参考
capistrano-net_storage を使ってみた
イントロ
小さいプロジェクトで capistrano を使っていると、最初は問題ないものの、気づいたらサービスが成長してサーバーが増えてきて、デプロイに時間がかかってくる、という話はよくある(?)と思う。
デプロイに時間がかかると色々とストレスで、所謂 pull 型 deploy を検討したくなってくる。
今の pull 型 deploy ってどんなものがあるのだろう、という疑問から色々調べてみて、最終的には capistrano-net_storage を採用することにした。
capistrano-net_storage を使ってみて、
- pull 型 deploy の恩恵を受けられている
- 移行も問題なく行われた
- 数ヶ月運用した限りでは、大きな問題は出てない
ということで、ここまでの知見をまとめてみた。
前提
- 小規模 ~ 中規模なサービスです
- 色々と古臭い事情により、
Docker化までたどり着いていない capistranoを使っている- 現在のプロジェクトは、master にマージされたら即 deploy
- 頻度は一日 2 ~ 5 回
対抗馬
- sorah/mamiya: Faster deploy tool using tarballs and serf
- AWS CodeDeploy
- fujiwara/stretcher: Deployment tool with consul/serf event notification.
有名所はこのあたり、なのかな。
capistrano-net_storage の良いところ
他の候補と比べて優位に感じた部分。
- capistrano の plugin として実装されていて、現在 capistrano を使っているプロジェクトでも、移行が比較的楽
- デプロイ対象のサーバー側に、特別なミドルウェアをインストールする必要が無い
- 必要なものは
awscliだけ
- 必要なものは
capistranoの資産を活かせる
現状の環境と比較し、ちょっと pull 型にしてみたいんや! という自分のワガママに答えてくれたのが超嬉しい。
導入
公式
DeNADev/capistrano-net_storage: Capistrano Plugin for Fast Deployment via Remote Storage DeNADev/capistrano-net_storage-s3: Capistrano::NetStorage Plugin for Deployment via Amazon S3
capistrano-net_storage とは
絵を見れば、なんとなくどんな事をやっているかわかる。

- capistrano で pull 型 deploy の実装
DeNA先輩がメンテしていらっしゃる
使い方
REDAME.md の通り。以下を config/deploy.rb に書くだけ。
set :scm, :net_storage set :net_storage_transport, Capistrano::NetStorage::S3::Transport # デプロイ対象サーバー(図で言うところの `app server`)で unzip が無い場合はこちら set :net_storage_archiver, Capistrano::NetStorage::Archiver::TarGzip # s3 の bucket, prefix 名 set :net_storage_s3_bucket, 'capistrano-deployments' set :net_storage_s3_archives_directory, 'awesome-project'
感想
- 導入が楽で効果も高いし、コスパ良し。
- capistrano の良いところを使いつつ、pull 型 deploy できるのは嬉しい
- 中身をみたけど、しっかりと作られている印象
capistranoに乗っかっているので、元のやり方に戻したい!という場合でもすぐに戻せた- 「普通の deploy ->
capistrano-net_storageの deploy -> 普通の deploy」みたいのも動くのが嬉しい- 突然失敗しても安心して対応できる
- 別のやり方だと、こう簡単にはうまくいかないと思う
- デプロイ回数が多いプロジェクトなので「突然デプロイできなくなるのは困る」という大人の事情もあった
- 「普通の deploy ->
- 図の
(3)の download する部分がawscliで実装されている点に注意- deploy 対象のサーバーに
awscliを install する必要があることを意味する- 入っていないと、プラグインを自作することになる、と思う。
- デフォルトの
awscliが一番楽な気はするplugableになっていて、自分でカスタマイズできるようになっている
- deploy 対象のサーバーに
- deploy サーバーに zip が残るので、思わぬ容量増加に注意
まとめ
capistrano 使っているなら capistrano-net_storage 素晴らしいと思う。
現代にはもっと良い技術が沢山あり、そちらにサラッと乗り換えたいものの、色々過去の経緯なりで中々そうはいかないこともある。
そんな状況下で、「サーバー台数が増えてもデプロイに時間がかからない」はかなり心強い。
コスパの良いその場しのぎになった、というお話でした。
node-inspector を使わず mocha で debug する
イントロ
mocha (>3.1.0) で V8 inspector integration がサポートされたとかで、デバッグが楽になった。
今までは node-inspector を入れたり(しかもコイツが中々使いづらい…)、console.log 連打したりで、非常に効率が悪かった。
が、これを使うと chrome の console 上で色々できるので、少しマシになる。
環境
node (6.9.4)mocha (3.4.2)
やり方
spec の中で debugger を仕込む
--- a/spec/imageResizer_spec.js +++ b/spec/imageResizer_spec.js @@ -4,6 +4,10 @@ const endPoint = new Aws.Endpoint('http://localhost:4572'); const s3 = new Aws.S3({ endpoint: endPoint }); describe('imageResizer', () => { + beforeEach(() => { + debugger; + }); + it('desc', () => { console.log("test"); });
mocha で --debug-brk と --inspect option をつけて spec を実行する
% mocha --debug-brk --inspect --compilers js:babel-core/register spec/imageResizer_spec.js
Debugger listening on port 9229.
Warning: This is an experimental feature and could change at any time.
To start debugging, open the following URL in Chrome:
chrome-devtools://devtools/remote/serve_file/@60cd6e859b9f557d2312f5bf532f6aec5f284980/inspector.html?experiments=true&v8only=true&ws=127.0.0.1:9229/bdb841cb-6a37-45e7-ae6a-c922b628bae9
Debugger attached.
すると devtools://xxxx という url が発行されるので chrome で開く。

F8 (右上の右矢印ボタンでも良い)を押すと、以下のように debugger のところで止まる。
後はお好きなように、という感じですね。

未解決なこと
node 8.x.x 系だとうまくいかない。。
というか nodejs の更新早すぎィ!
RDSのインスタンス作成、タイプ変更等の時間を調べた
イントロ
よくわかってなかったので自分で実験。
会社でアップグレードする機会があったので、その予行練習の記録をまとめたものです。
準備
0 の状態から最小限の構成で確認したかったので、以下のようになった
- 管理画面から RDS を作成
- 管理画面から ec2 を作成(ubuntu)
- デフォルトの Security Group を attach する(RDS の Security Group がデフォルトの Security Group を許可する設定になっていたため)
- 立ち上げた ec2 に
mysql-clientを install するsudo apt-get update && sudo apt-get install mysql-client
- 管理画面から RDS を変更
- この結果を観察
インスタンスの作成
| Time(utc+9) | Event |
|---|---|
| Jul 9 9:37 AM | Finished applying modification to convert to a Multi-AZ DB Instance |
| Jul 9 9:28 AM | Applying modification to convert to a Multi-AZ DB Instance |
| Jul 9 9:28 AM | DB instance created |
| Jul 9 9:28 AM | DB instance restarted |
- クリックしてからイベント表示まで、3 ~ 5 分ほどかかる。
- URL が表示されていれば、Status が
modifyingになっていても、接続は可能Applying modification to convert to a Multi-AZ DB Instanceのタイミングでは、もう URL は発行されている
- Multi AZ 構成だと、インスタンス作成に少なくとも 10 分程度かかる模様。
m3.xlarge,m3.large,t2.smallで検証したところ、インスタンス作成時間にインスタンスタイプは関係ないっぽい- 作成時間にほとんど差が無かった
- 検証に偏りがあるかもしれない可能性は若干ある
インスタンスタイプの変更
AWS RDSのインスタンスタイプ変更やメンテ再起動にかかる時間は約1分〜5分 - Qiita
を拝借。sleep の時間を 5 秒に変えている
ubuntu@ip-172-31-25-166:~$ while true; do > mysqladmin ping -h test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com -u root -ppassword > date > sleep 5 > echo "---------" > done mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqld is alive Sun Jul 9 01:30:17 UTC 2017 --------- ... --------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqld is alive Sun Jul 9 01:38:44 UTC 2017 --------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqladmin: connect to server at 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' failed error: 'Can't connect to MySQL server on 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' (111)' Check that mysqld is running on test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com and that the port is 3306. You can check this by doing 'telnet test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com 3306' Sun Jul 9 01:38:49 UTC 2017 --------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqladmin: connect to server at 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' failed error: 'Can't connect to MySQL server on 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' (110)' Check that mysqld is running on test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com and that the port is 3306. You can check this by doing 'telnet test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com 3306' Sun Jul 9 01:41:01 UTC 2017 # <= 5 秒おきに ping を飛ばすが、これだけ刺さってしまった --------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqld is alive Sun Jul 9 01:41:06 UTC 2017 ...
| Time(utc+9) | Event |
|---|---|
| Jul 9 11:06(?) AM | — インスタンスの status が modifying -> available になる — |
| Jul 9 11:04 AM | Finished applying modification to allocated storage |
| Jul 9 10:47 AM | Applying modification to allocated storage |
| Jul 9 10:47 AM | Finished applying modification to DB instance class |
| Jul 9 10:41 AM | — ping が通るようになる — |
| Jul 9 10:40 AM | Multi-AZ instance failover completed |
| Jul 9 10:39 AM | DB instance restarted |
| Jul 9 10:39 AM | Multi-AZ instance failover started |
| Jul 9 10:38 AM | — ping が通らなくなる — |
| Jul 9 10:31 AM | Applying modification to database instance class |
| Jul 9 10:30 AM | Performance Insights has been disabled |
| Jul 9 10:30 AM | Monitoring Interval changed to 60 |
ストレージタイプの変更
General Purpose(SSD) -> Provisioned IOPS(SSD) に変更する。
この変更だとダウンタイムは発生しない。
mysqladmin ping も変更の間、全部通ったことを確認した。
なお「Magnetic からの変更」「Magnetic への変更」はダウンタイムが発生する模様。
ストレージタイプの使用 - Amazon Relational Database Service
| Time(utc+9) | Event |
|---|---|
| Jul 15 6:55 PM | Finished applying modification to allocated storage |
| Jul 15 6:45 PM | Applying modification to allocated storage |
| Jul 15 6:45 PM | Finished preparing for modification of storage |
| Jul 15 6:44 PM | Performance Insights has been disabled |
| Jul 15 6:44 PM | Monitoring Interval changed to 60 |
- ストレージの容量に比例して、変更の時間が長くなる可能性はありそう
- リードレプリカを作成している場合は以下の点を考慮する必要がある
- マスターと容量は合わせる必要がある
- マスターが 100G ならば、レプリカは 100G 以上でないといけない
- マスターとストレージタイプを合わせる必要は無い
- マスターが PIOPS で、レプリカが Magnetic は 可能
- Amazon RDS のストレージ - Amazon Relational Database Service
- マスターと容量は合わせる必要がある
mysql のバージョンアップ
5.6.35 -> 5.7.17 にしてみた。ダウンタイムが発生。
どうやらテーブルの型変換が強制的に行われるので、そのようなテーブルがあると結果が大きく変わりそう
MySQL DB エンジンのアップグレード - Amazon Relational Database Service
--------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqld is alive Sat Jul 15 10:10:21 UTC 2017 --------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqladmin: connect to server at 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' failed error: 'Can't connect to MySQL server on 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' (111)' Check that mysqld is running on test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com and that the port is 3306. You can check this by doing 'telnet test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com 3306' Sat Jul 15 10:10:26 UTC 2017 ... mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqladmin: connect to server at 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' failed error: 'Can't connect to MySQL server on 'test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com' (111)' Check that mysqld is running on test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com and that the port is 3306. You can check this by doing 'telnet test.celqgbwlf3q4.ap-northeast-1.rds.amazonaws.com 3306' Sat Jul 15 10:13:43 UTC 2017 --------- mysqladmin: [Warning] Using a password on the command line interface can be insecure. mysqld is alive Sat Jul 15 10:13:48 UTC 2017 ---------
| Time(utc+9) | Event |
|---|---|
| Jul 15 7:19 PM | Finished DB Instance backup |
| Jul 15 7:16 PM | Backing up DB instance |
| Jul 15 7:15 PM | Database instance patched |
| Jul 15 7:15 PM | Finished DB Instance backup |
| Jul 15 7:15 PM | Updated to use DBParameterGroup default.mysql5.7 |
| Jul 15 7:13 PM | DB instance restarted |
| Jul 15 7:13 PM | – ping が通るようになる– |
| Jul 15 7:12 PM | DB instance shutdown |
| Jul 15 7:10 PM | – ping が通らなくなる– |
| Jul 15 7:10 PM | Backing up DB instance |
| Jul 15 7:10 PM | DB instance shutdown |
| Jul 15 7:05 PM | Performance Insights has been disabled |
| Jul 15 7:05 PM | Monitoring Interval changed to 60 |
注意事項
- snapshot 作成中は instance を変更できない
- snapshot の作成時間は、自動バックアップのイベントを見てれば大体予想がつく
まとめ
- 自動バックアップの時間帯に注意
- スナップショット作成中はインスタンスの変更ができない
- メンテナンス時間をとる場合は、作業が後ろ倒しになってしまうので気をつける
- インスタンスタイプ変更によるダウンタイムは 3 ~ 5 分程度
- Multi-AZ のフェイルオーバーのタイミングでダウンタイムが発生する
- この時間は DB にアクセス出来ないため、メンテナンス時間を設けることを推奨
- 復旧後、管理画面上は
modifyingになっていたものの、接続は可能- インスタンスタイプ変更から、
availableまでの時間(= 全部完了の時間)は 約 35 分
- インスタンスタイプ変更から、
- mysql のバージョンアップによるダウンタイムは 3 分程度
- リードレプリカの設定をしている場合、storage の設定に気をつける
- マスターのアップグレードをするために、リードレプリカのアップグレードが必要になる場合がある
- 検証は行ったけど、実際のデータが投入されてないと、実際の作業時間の見積もりは難しい
- 変更前に手動スナップショットは作成しておくと、万が一の事があっても安心
- 無いとは思うが、いきなりインスタンスが消されても、手動スナップショットは残るため
参考
【AWS】RDSのインスタンスタイプ変更にかかる時間を調べてみた | Developers.IO AWS RDSのインスタンスタイプ変更やメンテ再起動にかかる時間は約1分〜5分 - Qiita
Docker と Vagrant で dotfiles をテストする
イントロ
で書いたとおり、最近は自分の dotfiles を MItamae で管理している。
運用していく中で、ちょっと複雑な receipe を書いた時、「これ試したいけど、いきなりぶっこむのはちょっとなぁ…」と思うようになった。
そこで MItamae を試すだけ試して、満足したら廃棄できる環境を作ってみた。
ついでに、その sandbox 的環境をテストする serverspec も一緒に書いたので、まとめてみた。
準備
Dockerfile.serverspec
ローカルに serverspec をインストールするのは、ruby に依存してしまうのでナシ。
そこで serverspec を実行する Docker コンテナを用意した。
よく docker-api を使って serverspec でテストするやり方を見かけるけど、Docker コンテナの中で docker-api を使えないので、ssh 接続でテストする。
FROM ruby:2.4.1-alpine
RUN apk update && apk add openssh-client && echo -e 'Host *\nUseRoaming no' >> /etc/ssh/ssh_config
ENV SERVERSPEC_VERSION 2.39.1
RUN gem install serverspec -v ${SERVERSPEC_VERSION}
WORKDIR /serverspec
Vagrant
cookbook を試す環境は Vagrant で用意した。
最初はこれも Docker でコンテナを用意してやっていたけど、serverspec からアクセスするのはコンテナではなくイメージなので、テストが失敗する
(状況を見るとそのような挙動に見える)
# 以下は Docker で環境を作って、serverspec でテストするパターンを試したときのログ
# `ubuntu`(レシピ実行場所) で bash を起動
$ docker-compose run --rm ubuntu bash
# MItamae を install
root@a16bec43ae35:/home/root# bin/setup.sh
# レシピを実行する
root@a16bec43ae35:/home/root# bin/mitamae local cookbooks/git/default.rb
INFO : Starting MItamae...
INFO : Recipe: /home/root/cookbooks/git/default.rb
INFO : package[git] installed will change from 'false' to 'true'
# git が install された
root@a16bec43ae35:/home/root# which git
/usr/bin/git
# `serverspec` (serverspec 実行用コンテナ)で sh を起動
$ docker-compose run --rm serverspec sh
# spec を実行する。`docker-compose` を使うことで `ubuntu` で名前解決している
/serverspec # TARGET_HOST=ubuntu rspec spec/git_spec.rb
Package "git"
should be installed (FAILED - 1)
Failures:
1) Package "git" should be installed
On host `ubuntu'
Failure/Error: it { should be_installed }
expected Package "git" to be installed
/bin/sh -c dpkg-query\ -f\ \'\$\{Status\}\'\ -W\ git\ \|\ grep\ -E\ \'\^\(install\|hold\)\ ok\ installed\$\'
# ./spec/git_spec.rb:4:in `block (2 levels) in <top (required)>'
Finished in 0.26349 seconds (files took 0.62787 seconds to load)
1 example, 1 failure
Failed examples:
# テストを実行しても、ssh で接続した世界には git が入っていない
rspec ./spec/git_spec.rb:4 # Package "git" should be installed
レシピを実行した後に docker commit して、もう一度 image を build して serverspec を走らせてもできたが、やってみてあまりに面倒に感じたので、スパッとやめてしまった。
ということで一周戻って Vagrant で環境を作ることになった。
現在のディレクトリを自動的に sync してくれるのも地味に助かった。
Vagrant.configure("2") do |config| config.vm.box = "ubuntu/xenial64" config.vm.network "private_network", ip: "192.168.33.10" end
レシピ実行
昔なつかし、vagrant ssh からのレシピ実行
$ vagrant up $ vagrant ssh ubuntu@ubuntu-xenial:~$ cd /vagrant ubuntu@ubuntu-xenial:/vagrant$ bin/setup.sh + mitamae_version=1.3.2 + mitamae_cache=mitamae-1.3.2 + [ -f bin/mitamae-1.3.2 ] + uname + mitamae_bin=mitamae-x86_64-linux + wget -O bin/mitamae-x86_64-linux.tar.gz --max-redirect 3 -q https://github.com/k0kubun/mitamae/releases/download/v1.3.2/mitamae-x86_64-linux.tar.gz + tar xvzf bin/mitamae-x86_64-linux.tar.gz mitamae-x86_64-linux + rm bin/mitamae-x86_64-linux.tar.gz + mv mitamae-x86_64-linux bin/mitamae-1.3.2 + chmod +x bin/mitamae-1.3.2 + ln -sf mitamae-1.3.2 bin/mitamae ubuntu@ubuntu-xenial:/vagrant$ bin/mitamae local cookbooks/git/default.rb INFO : Starting MItamae... INFO : Recipe: /vagrant/cookbooks/git/default.rb
テスト
spec_helper.rbに vagrant に ssh 接続する情報を書く- host は
Vagrantfileに書いた private な ipaddress を指定 userとkeyはvagrant ssh-configの内容をそのまま使う
- host は
- コンテナから
serverspecを実行する
require 'serverspec' require 'net/ssh' set :backend, :ssh if ENV['ASK_SUDO_PASSWORD'] begin require 'highline/import' rescue LoadError fail "highline is not available. Try installing it." end set :sudo_password, ask("Enter sudo password: ") { |q| q.echo = false } else set :sudo_password, ENV['SUDO_PASSWORD'] end options = Net::SSH::Config.for(host) options[:user] = 'ubuntu' options[:keys] = '.vagrant/machines/default/virtualbox/private_key' set :host, ENV['TARGET_HOST'] || "192.168.33.10" set :ssh_options, options # Disable sudo set :disable_sudo, true Dir['./spec/shared/*'].each { |f| require f }
$ docker run --rm -it -v ${PWD}:/serverspec --net=host dotfiles_serverspec rspec spec/ubuntu_spec.rb ubuntu behaves like git Package "git" should be installed Finished in 1.15 seconds (files took 0.60525 seconds to load) 1 example, 0 failures
まとめ
ここまですると逆に面倒くさくなってきて、もはや趣味の領域に入りつつあります。
それと Mac 環境でのテストになってなくて、当初目標にしていた事が実現できたとは言い難い。
しかしながら、いつでも OS X を捨てられる準備をしておかないと、もし Apple がとんでもない改悪をしても、
それに耐え続けなければならなくなるし、私はそれを我慢し続けられるほど大人では無いという自覚がある。
ということで目的とはズレてしまったが、 Mac を捨てる準備を整えることができた、という副産物が得られたので良しとしたい。
それと、少しづつテストやレシピを補完していきたい。
webpack を使った Google Chrome Extension づくり
イントロ
気が向いたので Google Chrome Extension を作成してみたくなった。
そこで最低限 webpack を使って、開発環境を整備できる環境を作ってみた。
色々調べてみて、一先ずこんなところに落ち着いた、というメモを残します。
似たようなのあるやろ
はい。あります。
- HaNdTriX/generator-chrome-extension-kickstart
- samuelsimoes/chrome-extension-webpack-boilerplate
- jhen0409/react-chrome-extension-boilerplate
- EmailThis/extension-boilerplate
方針
この記事では webpack を使って Google Chrome Extension を作り始められるところをまとめている。
というのも、既存のを参考にしながら試した結果、結局テンプレートを使うより、小さく自作するのが一番良いと思ったからです。
(一度 yeoman 使って、後で破綻し、とてもゲンナリした)
以下のようなルールを決めて環境を作っている。
ルールも小さく保って、今後も守りやすいようにしているつもり。
ディレクトリ構成
src 以下のディレクトリ構成は好きにすれば良いと思うけど、今のところ以下のようにしている。
% tree src/ -d src/ ├── _locales ├── images ├── scripts ├── styles └── views # React 使う場合は `components` のほうがいいかも
ディレクトリ構成は、Github で色々と repository を見て回ったものの、共通点が少なく、皆自由にやってるんだなという印象を受けた。 故に各自でしっくりくるディレクトリ構成を選べば良いと思う。自分は上記になった、という紹介。
ただ、i18n については _locales 固定なので注意が必要。
chrome.i18n - Google Chrome
初め方
webpack + ES6 を使った構成を作ってみる
$ yarn init $ yarn add -D webpack copy-webpack-plugin babel-loader babel-core babel-preset-es2015 $ touch .babelrc
webpack
以下は一例。
$ touch webpack.config.babel.js $ vi webpack.config.babel.js
import path from 'path';
import CopyWebpackPlugin from 'copy-webpack-plugin';
export default {
entry: {
contentScripts: path.join(__dirname, 'src', 'scripts', 'contentScripts.js'),
},
output: {
path: path.join(__dirname, "dist"),
filename: 'scripts/[name].bundle.js',
},
target: 'web',
devServer: {
contentBase: path.join(__dirname, 'dist'),
port: 9000,
hot: true,
},
module: {
rules: [
{
test: /\.js$/,
use: { loader: 'babel-loader' }
},
]
},
plugins: [
new CopyWebpackPlugin(
[
{
from: path.join(__dirname, 'src', 'manifest.json'),
to: path.join(__dirname, 'dist'),
}
]
)
]
};
補足
- entry は複数持つ可能性が高いので、object で指定したほうが良い気がする
content scriptやbackgroundなど、複数のファイルで構成されることが多いため- この辺の用語は Chrome拡張の開発方法まとめ その1:概念編 - Qiita がすごいわかりやすかった
copy-webpack-pluginはmanifest.jsonをdist/にコピーするために入れている- manifest.json とは、Google Chrome Extension の設定ファイル
- compile が不要なものは、まるっと dist にコピーする
manifest.json以外でも、例えば html はべた書きで書いたりする場合はCopyWebpackPluginの設定を足せばいい
js
$ touch src/scripts/contentScripts.js $ vi src/scripts/contentScripts.js
% cat src/scripts/contentScripts.js
console.log("Hello");
manifest.json
$ touch src/manifest.json
{
"manifest_version": 2,
"name": "name",
"version": "0.0.1",
"description": "",
"author": "mgi166",
"content_scripts": [
{
"matches": ["http://*/*", "https://*/*"],
"js": ["scripts/contentScripts.bundle.js"]
}
],
}
いざ開発
- まずは「デベロッパーモード」にチェックを付ける
- その後パッケージ化されていない拡張機能を読み込む、というボタンを押して、
dist/ディレクトリを読み込むようにする- 一度は webpack コマンドを実行し、
dist/を作成する必要がある
- 一度は webpack コマンドを実行し、

これで自作する拡張機能が登録できたと思う。
後は
$ webpack --watch
で変更を監視して、後は src/ 以下のファイルをいじれば ok
compile が終わったソースを読み込む場合は、chrome://extensions/ の拡張機能で、リロードをするのを忘れないようにする。(これがめんどいのだが…)
まとめ
webpack を通して Google Chrome Extension を開発するまでの流れを書いてみた。
後はやりたいことに応じて、好きなようにできると思う。
Wercker で build API を叩いてもテストが始まらない件
イントロ
最近 Wercker を使っています。 Wercker でも CircleCI と同じように build を行う API があるのですが、どうしても build の API が叩けなくてハマったのでメモ。
現象
build API を使って build を行うと、Invalid stack というエラーが出る。
エラーメッセージの意味がよくわからない。
$ jq . -c <<JSON | curl -s -d @- -H 'Authorization: Bearer token' -H 'Content-type: application/json' 'https://app.wercker.com/api/v3/builds' | jq . { "applicationId": "applicationid", "branch":"develop", "envVars":[ {"key":"HOGE_FOO","value":"true"} ] } JSON { "statusCode": 400, "error": "Bad Request", "message": "Invalid stack, only stack 1 and 5 are supported for builds" }
結論
build API を使うのではなく、Runs API を使う。
現在の Wercker は二つの環境が同居していて、その環境のことを Stack と呼ぶ。
古い環境を Classic stack と呼び、新しい環境を Docker Workflows Stack というらしい。
今は新しく環境を作ると、全て Docker Workflows Stack になるようで、build API は古い stack 用の API で、Runs API は新しい stack 用の API となっている。
どちらも叩くと CI の build が走る。
したがって最近作った CI の場合、runs API を叩いて、build を走らせる必要がある、というネタでした。
なお、必須パラメータが Build API とは若干異なり、Runs API では、pipelineId という値が必須になる。
pipelineId というのは、repository を選択して、Workflows タブから下の方にある、pipeline 名をクリックしたときのURL から取得する。(app.wercker.com/{user}/{reponame}/workflows/pipeline/{pipelineId})
API 経由でもちょっと面倒くさいけど頑張れば取れる。


curl で叩く場合、以下のようになる。
jq . <<JSON | curl -X POST -s -d @- -H "Authorization: Bearer token" -H 'Content-type: application/json' https://app.wercker.com/api/v3/runs | jq . { "pipelineId": "pipeline_id", "branch": "develop", "envVars": [ { "key": "HOGE_FUGA", "value": "true" } ] } JSON
おわり
Runs ってなんだよ… 「走る」かよ…
隅々まで document を読まないと、こういう恥をかきます。
こんなつまらないことでハマって、初 StackOverflow デビューしました。
速攻で英語の添削が入りました。おわり。